



Inference prices will plummet, so focus on user retention
Price optimization is getting done for you
Generative AI applications, from startups to trillion-dollar companies like Google, are considered “expensive” by the companies running them. Every time a Gen AI product serves a customer, a “high” cost is paid. This is to say, higher than cloud-only companies with 80% gross margins.
The perception of high cost was such a weakness that Microsoft's Satya Nadella was eager to exploit with the launch of Bing’s copilot.
This new Bing will make Google come out and dance, and I want people to know that we made them dance.
Forcing Google to use Generative AI inference results for users was seen as 10x more expensive than traditional search1, and Google didn't have monetization figured out. High costs and low monetization are concerns if demand for Gen AI products grows, which it has.
The demand for Generative AI has been staggering, with NVIDIA’s Gen AI datacenter product growing 400%2 in a year and OpenAI going from almost $0 to a $1.6B3 revenue run rate in two years. However, as the industry grows, the supply of Generative AI applications AND Generative AI inference providers grows. But, as the oil industry says, “The cure for high oil prices is high prices”.
High prices induce competition on the hardware side and cost-saving techniques in training and using models.
5 major factors will drive Gen AI inference costs lower:
Traditional competition lowering prices, i.e., Google Gemini
Improvements in the training and inference ability of GPUs and Tensor Processing Units (TPUs), e.g., AMD MI300X (a GPU)
Software improvements working with GPUs, like NVIDIA’s TensorRT
Efficiency improvements in how models are designed and how inference happens, e.g., draft models
GPU capacity utilization improvements and contract discounts
Together, these combinations of supply-side improvements will result in a combinatorial collapse of prices, making inference super cheap. This will have meaningful benefits for where and how Gen AI is used, and how AI applications should be built.
Traditional competition leads to lower prices
The first order of the coming price decrease comes from the prosaic: competition. Competition that exists at all levels of the Gen AI stack: hardware and AI infrastructure reseller pricing.
Google Gemini Pro, announced mid-December, is priced at 1/10th the price of OpenAI’s GPT-4 Turbo. Lower prices are a way to induce developers to switch from OpenAI. Open source models see the benefits from price competition, too. After the launch of Mixtral 7b, a number of AI infrastructure companies announced successively lower prices for Mixtral’s use (all prices per 1M tokens, output, unless otherwise specified)4:
Together.ai: $0.6 (combined input and output tokens)
Anyslace.com: $0.5
PerplexityLabs: $0.28
Deepinfra: $0.27
New models and new infrastructure players will compete on price to win market share, driving down the price. These price wars will be aided by actually lower costs through new GPUs.
Hardware competition and improvements lead to lower prices
AMD recently announced the MI300, considered serious competition for NVIDIA’s H100. The MI300 is speculatively priced at or below $20,0005, about half the price of the NVIDIA H200 and still 50% less than the list price of the H100.
In addition to the MI300, most hyperscalers have announced their own chips for AI. Google has its TPU, Microsoft the Maia 100, Amazon the Inferentia, and Meta (not a hyperscaler) has its MTIA v100. These chips will reduce demand for NVIDIA chips and lower the hyperscalers' own cost structure. These savings can be passed on to customers. But it’s not just hardware competition and improvements that help. It’s also software.
Software improvements, combined with hardware improvements, lead to 18x improvements
GPUs operate with more than just physical hardware; software is also a key component when using GPUs. NVIDIA released TensorRT, an SDK for compiling and optimizing LLMs for inference, enabling developers to “optimize inference using techniques such as quantization, layer and tensor fusion, kernel tuning, and others on NVIDIA GPUs.”6
From Nvidia’s Q4 2023 earnings:
“Combined, TensorRT-LLM and H200, increased performance or reduced cost by 4x in just one year. With our customers changing their stack, this is a benefit of CUDA and our architecture compatibility. Compared to the A100, H200 delivers an 18x performance increase for inferencing models like GPT-3.”
Improving performance with hardware and software makes a clearly large difference, but there are ways to structure models differently that lower prices, too. Llama 2 sees a 4.6x improvement in inference performance when using an H100 with TensorRT-LLM versus an A100.
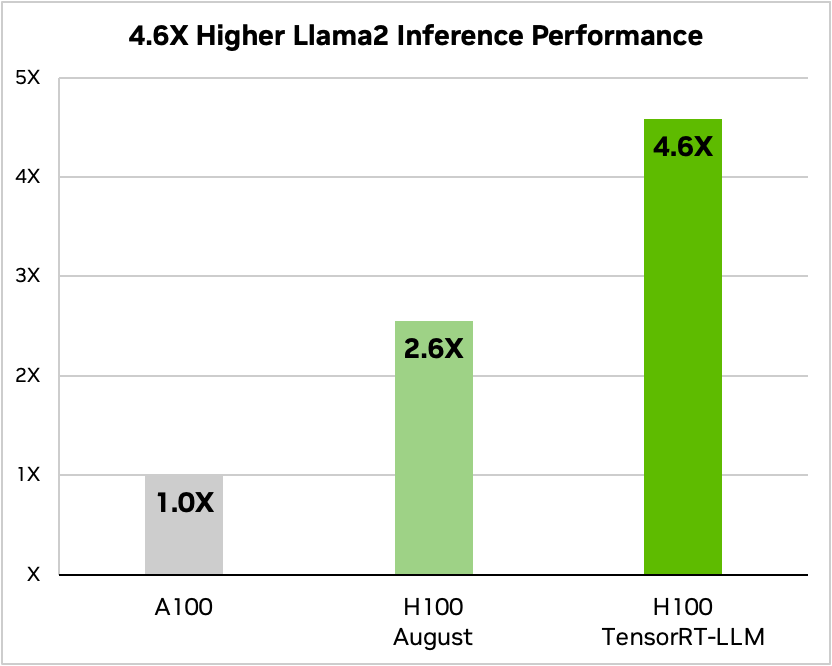
Model design and service architecture could lower costs by 90%
Models get better, more capable, and developers learn techniques to improve their performance. In addition to model compression and optimization techniques that are more accessible through TensorRT, how models are put together can lower their cost.
Techniques that improve the latency, or decrease the cost, associated with inference are continuing to grow. Last year a team from Google published a paper on Speculative Decoding.7
From the abstract, “At the heart of our approach lie the observations that (1) hard language-modeling tasks often include easier subtasks that can be approximated well by more efficient models, and (2) using speculative execution and a novel sampling method, we can make exact decoding from the large models faster, by running them in parallel on the outputs of the approximation models, potentially generating several tokens concurrently, and without changing the distribution.”
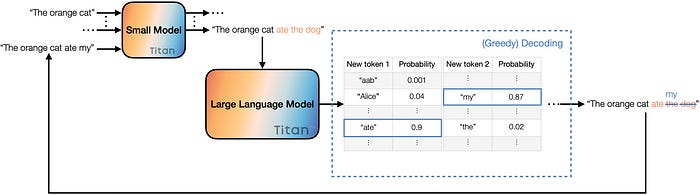
Benefits from this technique have been benchmarked at 2-10x improvements in model latency and speed, which can also translate into cost savings. Since the technique came out, there have been other enhancements, like speculative sampling8 (2-3x improvement) and Cascading Speculative Drafting9 (72% speedup on speculative decoding). The pace of these techniques will improve model latency/reduce costs.
Longer contracts and better capacity utilization could further drop costs
Back into the realm of general business, there is room to push costs down by signing longer contracts with hyperscalers and hyperscalers making better use of actual GPU utilization. Signing longer-term contracts can push the costs down by 20% or more (depending on the hyperscaler and the length of time).
At the same time, actual GPU utilization by customers is estimated at around 60% for some of the hyperscalers. Currently, that additional time is not resold, but some better aggregation of GPU time is possible, further freeing up resources.10
Getting a sense of what is actually possible in terms of cost reduction becomes challenging. Partly it depends on whether the market demands higher performance and slower lag times or lower cost.
At the very least, NVIDIA H200s, utilizing TensorRT-LLM, and speculative decoding might see a 30x improvement in speed (or cost) versus GPT-3 on an A100. As newer chips are deployed, model techniques improve, and competition enters the market, the cost for inference is going to plummet.
How to think about this - it’s all about the users.
When developing computers and software in the 1980s and 90s, it was reasonable to think that Moore’s law would significantly lower the price of hardware. Even by the time something shipped. It was a reasonable move to build for higher performance systems today, knowing that the cost would come down significantly, making the software more accessible. From 1984 to 1997, the cost of 1 billion floating point operations per second decreased by almost 650x, from $20M to $30k. Another 14 years later it decreased 40k times down to $.75.11
The costs to run generative AI applications are going to plummet, meaning that the real value comes from delivering the best user experience today. Use the higher quality model, leverage emerging prompting techniques, and focus on building the best product and retaining users. Your cost optimization will got done for you.
Source notes
While there are numerous footnotes on this article, this post is largely a distillation, for my own benefit, of a number of posts from SemiAnalysis and FabricatedKnowledge. They are both excellent, excellent resources on understanding semiconductors and the business side of generative AI infrastructure.
Specifically, this post was initially inspired by this more detailed and excellent post on inference costs:

For additional resources and thoughts on Speculative execution/decoding, please see this highly informative post from Andrew Karpathy:
https://twitter.com/karpathy/status/1697318534555336961
NVIDIA datacenter revenue was reported $14.5B October ‘23 versus $3.8 the same period last year
https://www.theinformation.com/articles/openais-annualized-revenue-tops-1-6-billion-as-customers-shrug-off-ceo-drama
https://developer.nvidia.com/tensorrt
https://arxiv.org/abs/2211.17192
https://arxiv.org/abs/2302.01318
https://browse.arxiv.org/html/2312.11462v2
Sourced from expert interviews
https://en.wikipedia.org/wiki/FLOPS#Hardware_costs