


Financial Agent Project; 2023 Investing Look back
Financial Agent Project; 2023 Investing Look back
Investing is a craft of continuous learning, and even good years have lessons to teach. While 2023 was a tough year in the private markets (and many of those mistakes were made in 2021 and 2022), 2023 was actually a great year in the public markets.
In the public markets (with my active portfolio); I edged out NASDAQ - my public benchmark. But I felt performance could have been much better. To improve my performance, particularly not doing research fast enough and being emotional about valuation, I decided to build a ‘Financial Agent’.
This post is divided into a a brief summary of my 2023 public market investing and then a look at my financial agent project.
Note: if you what youre interested in is my ‘financial agent’ project, just skip down to that section. My tl;dr on investing is I edged out QQQ, believe I should have done much better, and am building something in Gen AI to help.
2023 stock market performance and why I decided to build a financial agent
To analyze 2023’s public market trades I looked at:
Entry and exit decisions
Trades considered but not taken
High performing stocks I completely missed
Entry and Exits
I try to make few actual trade decisions recognizing that very short term trades are not my strength. Instead, I look for a solid hypothesis on why a stock is undervalued relative to expectations, decide on if/when the market my turn around, and then look to buy.
I entered 20 positions and exited 13.
All exited positions were ones that I thought my core hypotheses were wrong.
Of ones I exited, I regret 2. I’ll come back to these.
Trades considered but not made
My public anti-portfolio contains mostly right decisions with a couple of big misses. I actively considered about 90 trades (and made 20 of those).
My trades made outperformed my basket of ideas considered. A naive weighting (not looking at when capital was actually deployed) showed:
Trades made: +41%
All ideas: +31%
All ideas had 7 big stock movements I missed, including: SPOT (+123%), TSLA (+133%), NVDA (+149%), META (+90%), SYM (+107%), and then Solana (+600%) and Bitcoin (+115%). This is from the time of the idea to the end of 2023.
The reasons missed were almost all based on intuition: high valuation (NVDA), fundamental concern about the actual tech/company (SPOT, BTC, SOL), and then insufficient research on the underlying company (TSLA, SYM).
Trades not even considered
Limiting to US stocks, that aren’t penny stocks, and with a minimum market cap and volume, there were ~90 stocks in the US that grew over 100% in 2023. A number of those were outside my circle of competence (I know nothing about Pharma). But there were still many good opportunities to make money. I missed these because I wasn’t considering a wide enough base of companies. I was too narrow, based on my own limited time.

My own 2023 evaluation and 2024 go forward.
I look at my performance and see 2 major issues:
Not actively evaluating enough companies
Being too emotional on valuation
My fix is a personal project I’m calling my own ‘Financial Agent’.
2024 Financial Agent and Personal project
LLMs have a clear role in parsing through large amounts of information. Machine learning has been employed in the stock market for decades, and NLP is used extensively. Generative AI is accessible to most people.
To address my misses in trading, I started developing my own financial agent. It’s an iterative process, with liberal use of GPT-4 to help code, but there’s a quick time to value. It’s also fun and helpful.
The actual plan of what I’m building is common. I’ve seen a number of companies commercializing this or doing it themselves. Incumbents are also rolling out pieces of this through earnings call summarization.
My initial system is below. It’s focused on public markets, through private seems quite doable. The basic idea is: ingest information > analyze it > synthesize it. It is not a decision making system, it’s a briefing system.
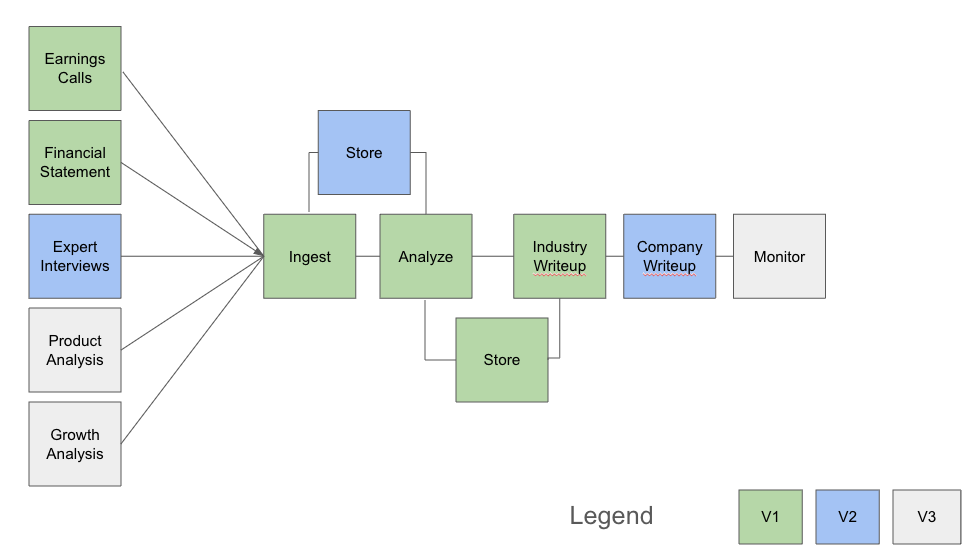
My workflow is to experiment in chatGPT, code it in python, then basically store everything to disk. Im using GPT-4 for the AI, Cursor for my IDE, and FinancialModelingPrep.com for the vast majority of the current data.
The current process flow
I fetch a couple of years of quarterly earnings calls and the comparable amount of financial statements.
I then iterate over each quarter and store the analysis. An example is NVIDIA’s FY 2024, Q3 earnings call, quick transcript.
**Changes in Growth and Margins Drivers:**
There's a discernible link between the strong Data Center segment and improved margins, with gross margin expansion to 74-75%. NVIDIA's strategic pivot towards a higher-margin, recurring revenue model through its software and services is a move that many in the tech sector have aimed to replicate but few have executed with such finesse.
From there I load each earnings call analysis into the context window and then look for ‘meta’ trends across the earnings calls.
The enterprise adoption wave of AI marked a strategic win, supported by enterprise software integrations with industry behemoths such as Adobe, Microsoft, and ServiceNow, significantly leveraging the AI capabilities of NVIDIA's technology. Moreover, NVIDIA's networking segment, which now exceeds a $10 billion annualized revenue run rate, also represents a remarkable achievement with a fivefold increase driven by demand for InfiniBand.
Finally, I’ll do an industry analysis, incorporating financial performance across the sectors.
Balance Sheet Insights:
Firstly, looking at the companies' total assets versus total liabilities, all except AVGO have their total assets exceeding total liabilities consistently. This is an indicative of healthy balance sheets. NVIDIA's assets have consistently outperformed liabilities in the long run, signaling good financial health and a lower level of risk for investors. Similarly, Intel's immense asset base regularly exceeds its liabilities, implying less financial stress and good corporate health. AMD, while having the smallest asset base among the three, still consistently has more assets than liabilities, pointing towards good financial status.
AVGO, however, depicts a different scenario with total liabilities closing in on total assets over the periods.
The more context loaded into memory the more the model tends to drift, but as a way to get up to speed on a company, monitor information, or catch trends, it’s helpful.
What I’ve learned so far
Geerative AI helps me. Even in sectors I try to stay on top of directly.
The financial agent has caught key pieces of information about companies that I’ve missed. An initial paradigm was “chat about a PDF”, allowing people to interactively ask questions. Chatting is not the ideal approach, here. Charlie Munger opined about the value of a checklist.
To that end, I made a standardized question set. This makes it easy to ensure almost everything gets asked. It’s also then possible to ask “Did I miss anything?”. Ive compared GPT-4s analysis to my haphazard approach to stock analysis and it catches things I miss.
Context windows and hallucinations are addressable problems
The more context, the longer the conversation, the less useful the AI becomes. This is like working with a person: the more tasks, the more overwhelmed they are, the less useful.
At my scale, which is a limited set of companies where I have familiarity, these issues aren’t worrying. When/if I scale up to a larger universe of stocks, it’ll become a concern.
Evaluations, Information Sources, and Questions
GPT-4 natively has significant information about companies. The more advanced these models get, the more it seems to have. The ability to understand what information source actually improves the quality of analysis is an intriguing prospect.
What makes quality analysis is subjective and complex. A good investment ‘memo’ needs to recognize the company, the industry, and the macro environment. If a stock selection does poorly, disentangling luck from process is key. It’s harder to do this with qualitative insights in complex systems.
It should be possible to test adding sources of information to the the write-ups, and then have the LLM act as judge at scale. That will be complex and I worry the outcome won’t be useful, so it’s something I’m parking for awhile.
Coding with AI
My coding experience pre-AI was at best some scripting and light scraping. SQL, R, Python - data analysis. Generative AI has been a godsend for coding help. It clearly starts to lose the plot as context grows (but so do I). Cursor helps more than ChatGPT because GPT-4 gets embedded in my projects, with the right context. I have yet to try Github Copilot.
Future thoughts
There are clear areas I’ll build out, but as an information parsing service, Generative AI is hugely helpful. I think there’s a tendency to compare AI to “perfect” as opposed to the base case (a generic human/me). Generative AI catches things I dont and does the work much faster. It’s a huge help.
Architecting the system, iterating through how to improve the flow, are all important parts in getting the system right.
Other companies have built similar pipelines, some charges thousands to millions for it, but it’s a pretty effective “hobby” project.